一、 集合引入
在Java中,我们经常用到数组来存储数据。
但是数组的长度是不可变的,一旦在初始化数组时指定了数组长度,这个数组长度就是不可变的了。
而大多数实际应用中,数据的数量是没法确定的,并且有些数据具有一定映射关系。
比如学生身高 <张三—170>、<李四—160>、<王五—180>,这些数据就是有有映射关系的,需要保存这样有映射关系的数据,数组就有点无能为力了。
这时候就需要我们的集合出马了
集合就像书架、抽屉、购物袋、衣柜、保险柜这样存放物体的容器。
现实生活中,这样的容器很多,当然了在Java中集合的类型也很多,用来存放不同的对象,其功能也会有所不同。
有些方便存入和取出、有的具有排序功能、有的可以保证安全性等等
二、集合框架体系
集合主要由两大接口派生而来:
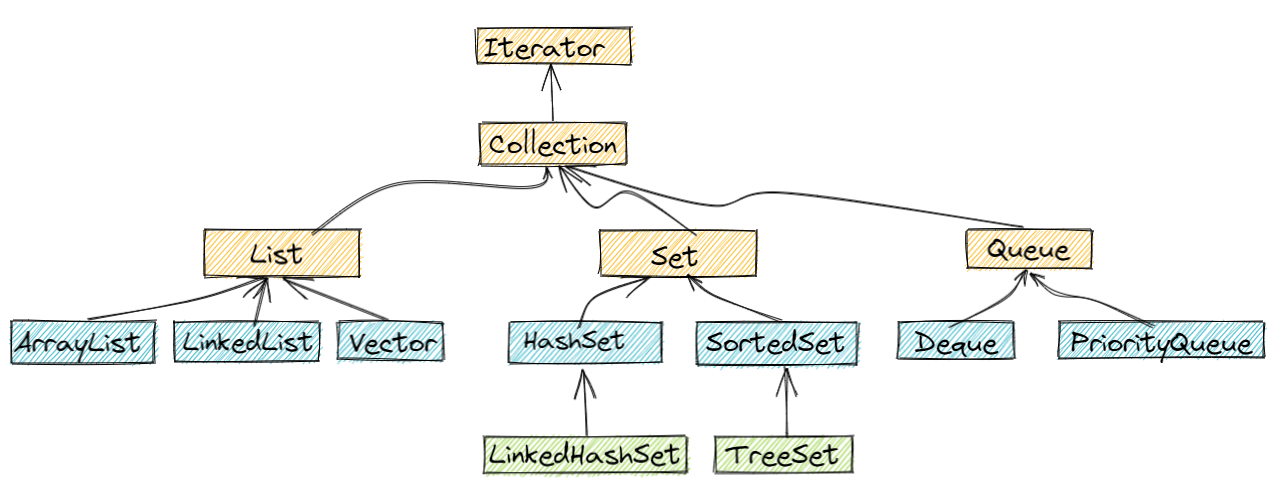
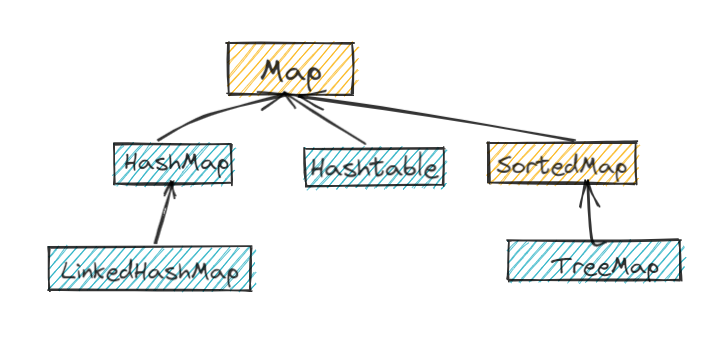
注意:以上图中只列举了主要的我们常接触继承派生关系,并没有列举所有关系。
黄色背景的为接口,其他背景的为实现类
| 接口名称 |
接口作用 |
List 接口 |
存储的元素是有序的、可重复的 |
Set 接口 |
存储的元素是无序的、不可重复的 |
Queue 接口 |
按特定的排队规则来确定先后顺序,存储的元素是有序的、可重复的 |
Map 接口 |
使用键值对(key-value)存储,key 是无序的、不可重复的,value 是无序的、可重复的,每个键最多映射到一个值 |
三 、Collection 接口
Collection接口作为List Set Queue 的父接口,提供了一些“公共资产”(公共方法) 给实现类(List Set Queue)使用。
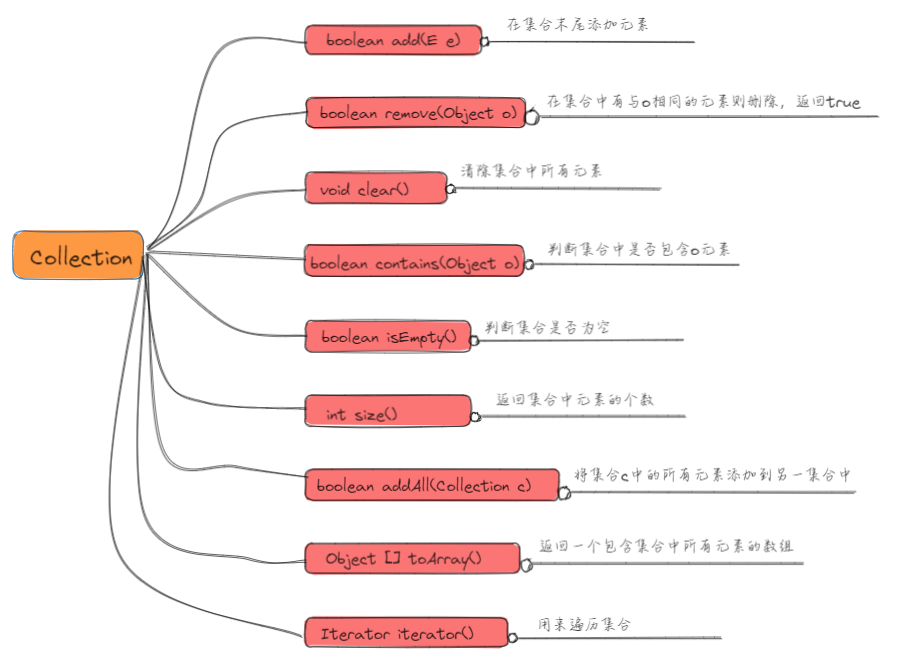
Collection既然作为父接口,一般不直接使用了,而是通过实现类来实现对集合的基本操作
接下来,我们以Collection 的实现类ArrayList 来具体演示一下集合的常用方法
①集合的基本操作
package com.xiezhr;
import java.util.ArrayList;
import java.util.List;
public class CollectionDemo {
public static void main(String[] args) {
List list = new ArrayList();
list.add("xiezhr");
list.add("xiezhrspace.cn");
list.add(666);
list.add(true);
System.out.println("list中添加元素后list:"+list);
System.out.println("list集合元素个数:"+list.size());
list.remove(0);
list.remove(true);
System.out.println("list中删除元素后list:"+list);
System.out.println("查找list中是否存在xiezhrspace.cn "+list.contains("xiezhrspace.cn"));
System.out.println("list集合是否为空"+list.isEmpty());
list.clear();
System.out.println("删除list集合中所有元素后list:" + list);
List list2 = new ArrayList();
list2.add("海贼王");
list2.add("火影忍者");
list2.add("名侦探柯南");
list.add(list2);
System.out.println("list2:" + list2);
System.out.println("list集合中添加list2后list:" + list);
System.out.println("list中是否存在list2中的元素"+list.containsAll(list2));
list.removeAll(list2);
list.add("画江湖之不良人");
System.out.println("list:" + list);
}
}
list中添加元素后list:[xiezhr, xiezhrspace.cn, 666, true]
list集合元素个数:4
list中删除元素后list:[xiezhrspace.cn, 666]
查找list中是否存在xiezhrspace.cn true
list集合是否为空false
删除list集合中所有元素后list:[]
list2:[海贼王, 火影忍者, 名侦探柯南]
list集合中添加list2后list:[[海贼王, 火影忍者, 名侦探柯南]]
list中是否存在list2中的元素false
list:[[海贼王, 火影忍者, 名侦探柯南], 画江湖之不良人]
②使用Iterator(迭代器) 遍历集合
所有实现Collection接口的集合都有一个iterator()方法用于遍历集合
package com.xiezhr;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
public class CollectionDemo {
public static void main(String[] args) {
List list = new ArrayList();
list.add("个人公众号:xiezhrspace");
list.add("个人博客:www.xiezhrspace.cn");
list.add(666);
list.add(true);
System.out.println("list中添加元素后list:"+list);
Iterator iterator = list.iterator();
while (iterator.hasNext()){
System.out.println(iterator.next());
}
}
}
list中添加元素后list:[个人公众号:xiezhrspace, 个人博客:www.xiezhrspace.cn, 666, true]
个人公众号:xiezhrspace
个人博客:www.xiezhrspace.cn
666
true
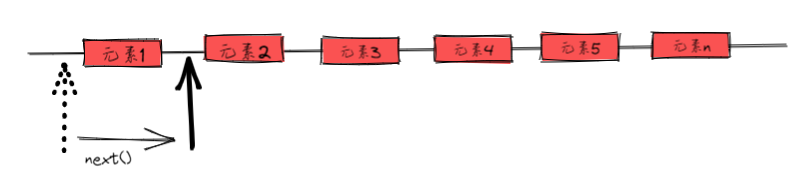
③使用for 循环增强 遍历集合
package com.xiezhr;
import java.util.ArrayList;
import java.util.List;
public class CollectionDemo {
public static void main(String[] args) {
List list = new ArrayList();
list.add("个人公众号:xiezhrspace");
list.add("个人博客:www.xiezhrspace.cn");
list.add(666);
list.add(true);
System.out.println("list中添加元素后list:"+list);
for (Object o : list) {
System.out.println(o);
}
}
}
list中添加元素后list:[个人公众号:xiezhrspace, 个人博客:www.xiezhrspace.cn, 666, true]
个人公众号:xiezhrspace
个人博客:www.xiezhrspace.cn
666
true
四 、List集合
List 集合简介
- List集合是一个有序、可重复的集合
- List集合中的每一个元素都有对应的顺序索引,默认按元素的添加顺序设置元素的索引,第一个添加到 List 集合中的元素的索引为 0,第二个为 1,依此类推
- List 集合允许使用重复元素,可以通过索引来访问指定位置的集合元素
- List 实现了
Collection 接口,它主要有两个常用的实现类:ArrayList 类和 LinkedList 类
4.1 ArrayList类
ArrayList有两种常见的构造方法
ArrayList() 构造一个初始容量为十的空列表ArrayList(Collection<? extends E> c) 构造一个包含指定集合的元素的列表。
ArrayList 类除了使用 Collection 接口的所有方法之外,还有其自己独特的方法
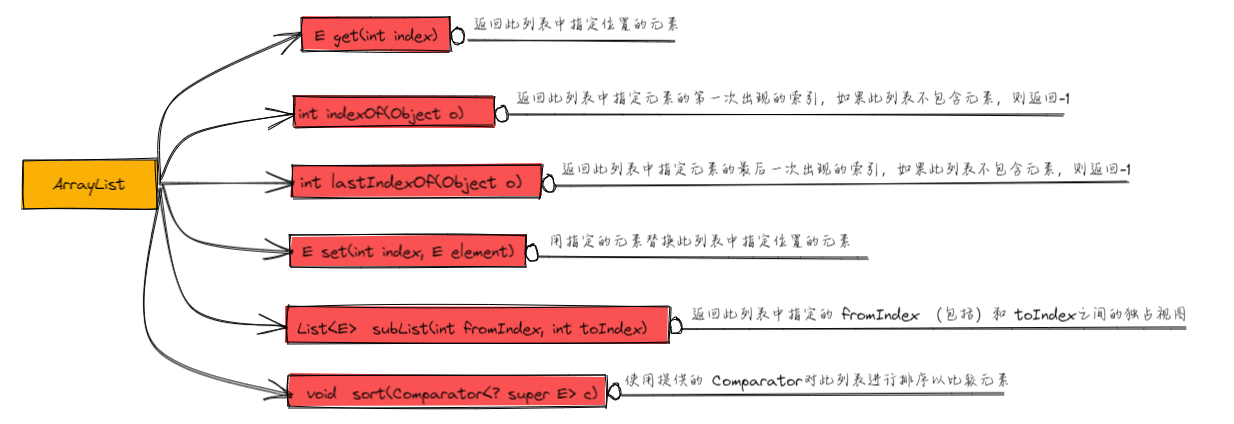
实践操作
package com.xiezhr;
import java.util.ArrayList;
import java.util.Comparator;
import java.util.List;
public class ArrayListDemo {
public static void main(String[] args) {
List list = new ArrayList();
list.add("萧炎");
list.add("美杜莎");
list.add("纳兰嫣然");
System.out.println("list原始值:" + list);
list.add(1,"xiezhr");
System.out.println("list在索引1处添加一个元素后:" + list);
System.out.println(list.get(3));
System.out.println("返回第一次出现“美杜莎”元素的位置:"+list.indexOf("美杜莎"));
System.out.println("返回最后一次出现“美杜莎”元素的位置:"+list.lastIndexOf("美杜莎"));
list.set(3,"小医仙");
System.out.println("用“小医仙”替换list索引为3的元素后:" + list);
List retlist = list.subList(0, 1);
System.out.println("返回的子集合是:" + retlist);
List sortlist = new ArrayList();
sortlist.add(34);
sortlist.add(5);
sortlist.add(56);
sortlist.add(9);
sortlist.add(-23);
System.out.println("原始list元素:" + sortlist);
sortlist.sort(Comparator.naturalOrder());
System.out.println("排序后得list:" + sortlist);
}
}
list原始值:[萧炎, 美杜莎, 纳兰嫣然]
list在索引1处添加一个元素后:[萧炎, xiezhr, 美杜莎, 纳兰嫣然]
纳兰嫣然
返回第一次出现“美杜莎”元素的位置:2
返回最后一次出现“美杜莎”元素的位置:2
用“小医仙”替换list索引为3的元素后:[萧炎, xiezhr, 美杜莎, 小医仙]
返回的子集合是:[萧炎]
原始list元素:[34, 5, 56, 9, -23]
排序后得list:[-23, 5, 9, 34, 56]
注意:
set(int index, Object element) 方法来改变 List 集合指定索引处的元素时,指定的索引必须是 List 集合的有效索引。当集合长度为 3,就不能指定替换索引为大于等于 处的元素,也就是说这个方法不会往list中添加新元素,只会替换原有元素indexOf()方法和 lastIndexOf() 方法,前者是获得指定list的最小索引位置,而后者是获得指定list的最大索引位置。前提条件是指定的对象在 List 集合中有重复的对象,否则这两个方法获取的索引值相同subList(1,3) 方法实际截取的是索引 1 到索引 2 的元素,并组成新的 List 集合
4.2 LinkedList类
LinkedList类有两种构造方法
LinkedList() 构造一个空列表LinkedList(Collection<? extends E> c) 构造一个包含指定集合的元素的列表,按照它们由集合的迭代器返回的顺序
LinkedList 除了包含 Collection 接口中的所有方法之外,还有其自己独特的方法
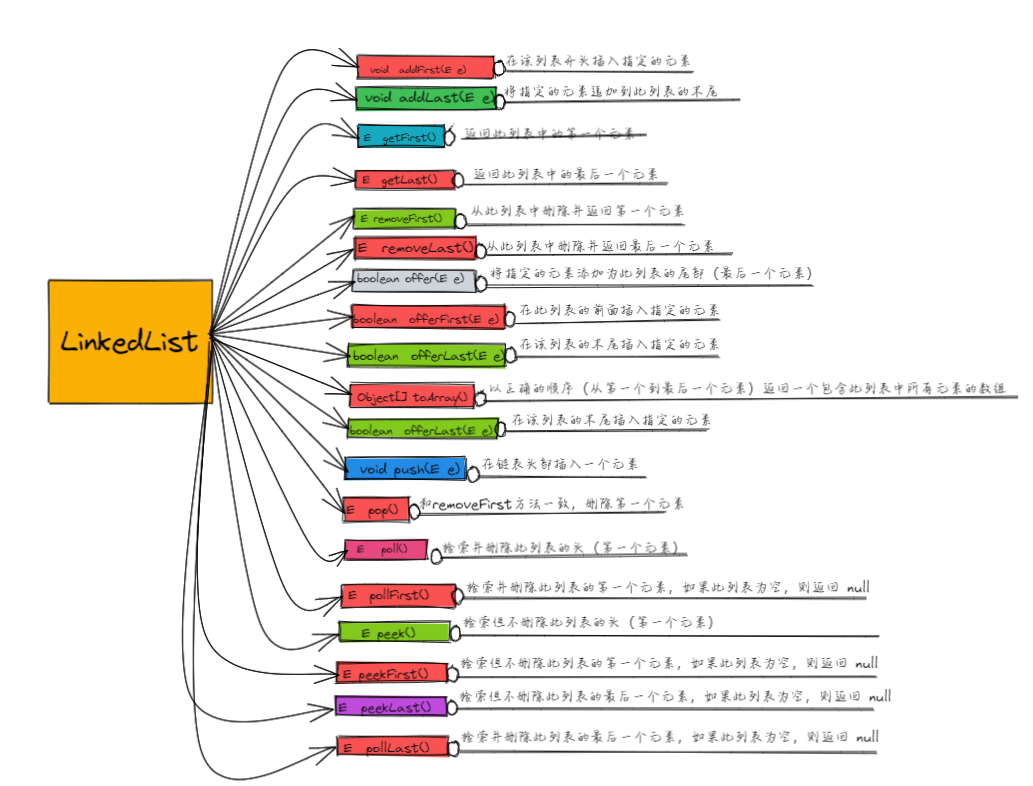
实践操作
package com.xiezhr;
import java.util.LinkedList;
public class LinkedListDemo {
public static void main(String[] args) {
LinkedList linkedList = new LinkedList();
linkedList.add("海贼王");
linkedList.add("火影忍者");
System.out.println("linkedList原始值:" + linkedList);
linkedList.addFirst("名侦探柯南");
System.out.println("linkedList使用addFirst开头插入一个值后:" + linkedList);
linkedList.addLast("忍者神龟");
System.out.println("linkedList使用addLast末尾插入一个值后:" + linkedList);
linkedList.push("鬼灭之刃");
System.out.println("linkedList使用push在集合开头插入一个值后:" + linkedList);
linkedList.offer("灵笼");
System.out.println("linkedList使用offer末尾插入一个值后:" + linkedList);
linkedList.add(2,"无间道");
System.out.println("linkedList在索引为2的位置插入一个值后:" + linkedList);
linkedList.offerLast("白蛇传");
System.out.println("linkedList使用offerLast末尾插入一个值后:" + linkedList);
linkedList.offerFirst("不良人");
System.out.println("linkedList使用offerFirst开头插入一个值后:" + linkedList);
System.out.println("获取下标为2的元素"+linkedList.get(2));
System.out.println("获取集合的第一个元素为:" + linkedList.getFirst());
System.out.println("获取集合最后一个元素为:" + linkedList.getLast());
System.out.println("使用peek()方法前:" + linkedList);
System.out.println("通过peek()获取第一个元素为:" + linkedList.peek());
System.out.println("使用peek()方法后:" + linkedList);
System.out.println("使用peekFirst方法前:" + linkedList);
System.out.println("通过peekFirst获取第一个元素为:" + linkedList.peekFirst());
System.out.println("使用peekFirst方法后:" + linkedList);
System.out.println("使用peekLast方法前:" + linkedList);
System.out.println("通过peekLast获取最后一个元素为:" + linkedList.peekLast());
System.out.println("使用peekLast方法后:" + linkedList);
System.out.println("使用poll方法前:" + linkedList);
System.out.println("通过poll获取第一个元素为:" + linkedList.poll());
System.out.println("使用poll方法后:" + linkedList);
System.out.println("使用pollFirst方法前:" + linkedList);
System.out.println("通过pollFirst获取第一个元素为:" + linkedList.pollFirst());
System.out.println("使用pollFirst方法后:" + linkedList);
System.out.println("使用pollLast方法前:" + linkedList);
System.out.println("通过pollLast获取最后一个元素为:" + linkedList.pollLast());
System.out.println("使用pollLast方法后:" + linkedList);
System.out.println("linkedList使用removeFirst方法前:" + linkedList);
linkedList.removeFirst();
System.out.println("linkedList删除第一个元素后:" + linkedList);
System.out.println("linkedList使用removeLast方法前:" + linkedList);
linkedList.removeLast();
System.out.println("linkedList删除最后一个元素后:" + linkedList);
System.out.println("linkedList使用remove方法前:" + linkedList);
linkedList.remove("忍者神龟");
System.out.println("linkedList删除指定元素后:" + linkedList);
}
}
linkedList原始值:[海贼王, 火影忍者]
linkedList使用addFirst开头插入一个值后:[名侦探柯南, 海贼王, 火影忍者]
linkedList使用addLast末尾插入一个值后:[名侦探柯南, 海贼王, 火影忍者, 忍者神龟]
linkedList使用push在集合开头插入一个值后:[鬼灭之刃, 名侦探柯南, 海贼王, 火影忍者, 忍者神龟]
linkedList使用offer末尾插入一个值后:[鬼灭之刃, 名侦探柯南, 海贼王, 火影忍者, 忍者神龟, 灵笼]
linkedList在索引为2的位置插入一个值后:[鬼灭之刃, 名侦探柯南, 无间道, 海贼王, 火影忍者, 忍者神龟, 灵笼]
linkedList使用offerLast末尾插入一个值后:[鬼灭之刃, 名侦探柯南, 无间道, 海贼王, 火影忍者, 忍者神龟, 灵笼, 白蛇传]
linkedList使用offerFirst开头插入一个值后:[不良人, 鬼灭之刃, 名侦探柯南, 无间道, 海贼王, 火影忍者, 忍者神龟, 灵笼, 白蛇传]
获取下标为2的元素名侦探柯南
获取集合的第一个元素为:不良人
获取集合最后一个元素为:白蛇传
使用peek()方法前:[不良人, 鬼灭之刃, 名侦探柯南, 无间道, 海贼王, 火影忍者, 忍者神龟, 灵笼, 白蛇传]
通过peek()获取第一个元素为:不良人
使用peek()方法后:[不良人, 鬼灭之刃, 名侦探柯南, 无间道, 海贼王, 火影忍者, 忍者神龟, 灵笼, 白蛇传]
使用peekFirst方法前:[不良人, 鬼灭之刃, 名侦探柯南, 无间道, 海贼王, 火影忍者, 忍者神龟, 灵笼, 白蛇传]
通过peekFirst获取第一个元素为:不良人
使用peekFirst方法后:[不良人, 鬼灭之刃, 名侦探柯南, 无间道, 海贼王, 火影忍者, 忍者神龟, 灵笼, 白蛇传]
使用peekLast方法前:[不良人, 鬼灭之刃, 名侦探柯南, 无间道, 海贼王, 火影忍者, 忍者神龟, 灵笼, 白蛇传]
通过peekLast获取最后一个元素为:白蛇传
使用peekLast方法后:[不良人, 鬼灭之刃, 名侦探柯南, 无间道, 海贼王, 火影忍者, 忍者神龟, 灵笼, 白蛇传]
使用poll方法前:[不良人, 鬼灭之刃, 名侦探柯南, 无间道, 海贼王, 火影忍者, 忍者神龟, 灵笼, 白蛇传]
通过poll获取第一个元素为:不良人
使用poll方法后:[鬼灭之刃, 名侦探柯南, 无间道, 海贼王, 火影忍者, 忍者神龟, 灵笼, 白蛇传]
使用pollFirst方法前:[鬼灭之刃, 名侦探柯南, 无间道, 海贼王, 火影忍者, 忍者神龟, 灵笼, 白蛇传]
通过pollFirst获取第一个元素为:鬼灭之刃
使用pollFirst方法后:[名侦探柯南, 无间道, 海贼王, 火影忍者, 忍者神龟, 灵笼, 白蛇传]
使用pollLast方法前:[名侦探柯南, 无间道, 海贼王, 火影忍者, 忍者神龟, 灵笼, 白蛇传]
通过pollLast获取最后一个元素为:白蛇传
使用pollLast方法后:[名侦探柯南, 无间道, 海贼王, 火影忍者, 忍者神龟, 灵笼]
linkedList使用removeFirst方法前:[名侦探柯南, 无间道, 海贼王, 火影忍者, 忍者神龟, 灵笼]
linkedList删除第一个元素后:[无间道, 海贼王, 火影忍者, 忍者神龟, 灵笼]
linkedList使用removeLast方法前:[无间道, 海贼王, 火影忍者, 忍者神龟, 灵笼]
linkedList删除最后一个元素后:[无间道, 海贼王, 火影忍者, 忍者神龟]
linkedList使用remove方法前:[无间道, 海贼王, 火影忍者, 忍者神龟]
linkedList删除指定元素后:[无间道, 海贼王, 火影忍者]
4.3 Vector类
Vector 是 List 的古老实现类,底层使用Object[] 存储,线程安全的
4.4 ArrayList 、 LinkedList 和 Vector区别
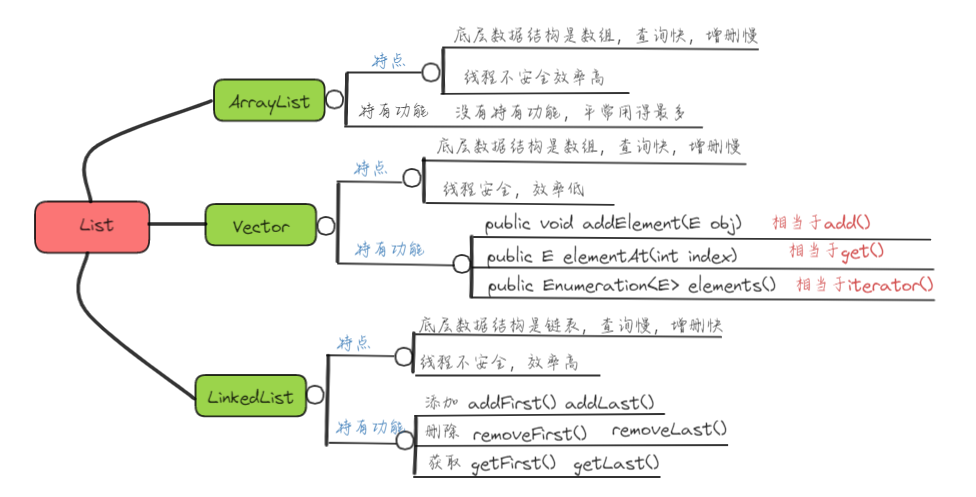
ArrayList 与 LinkedList 都是 List 接口的实现类- 实现
List接口方式的不同,所以对不同的操作具有不同的效率
ArrayList 和 LinkedList 都是不同步的,也就是不保证线程安全ArrayList 底层使用的是 Object 数组;LinkedList 底层使用的是 双向链表 数据结构ArrayList 采用数组存储,所以插入和删除元素的时间复杂度受元素位置的影响。 比如:执行add(E e)方法的时候, ArrayList 会默认在将指定的元素追加到此列表的末尾,这种情况时间复杂度就是 O(1)。但是如果要在指定位置 i 插入和删除元素的话(add(int index, E element))时间复杂度就为 O(n-i)。因为在进行上述操作的时候集合中第 i 和第 i 个元素之后的(n-i)个元素都要执行向后位/向前移一位的操作LinkedList 采用链表存储,所以,如果是在头尾插入或者删除元素不受元素位置的影响(add(E e)、addFirst(E e)、addLast(E e)、removeFirst() 、 removeLast()),时间复杂度为 O(1),如果是要在指定位置 i 插入和删除元素的话(add(int index, E element),remove(Object o)), 时间复杂度为 O(n) ,因为需要先移动到指定位置再插入LinkedList 不支持高效的随机元素访问,而 ArrayList 支持,通过get(int index) set(int index) 可以快速获取元素,修改元素- 创建
ArrayList 会在结尾预留一定容量的空间,而LinkedList 占用的空间比ArrayList 更多(空间除了存储数据之外还需要存储直接后继和直接前驱)
- 如果需要经常插入、删除操作来改变List集合的大小,则应该使用LinkedList集合
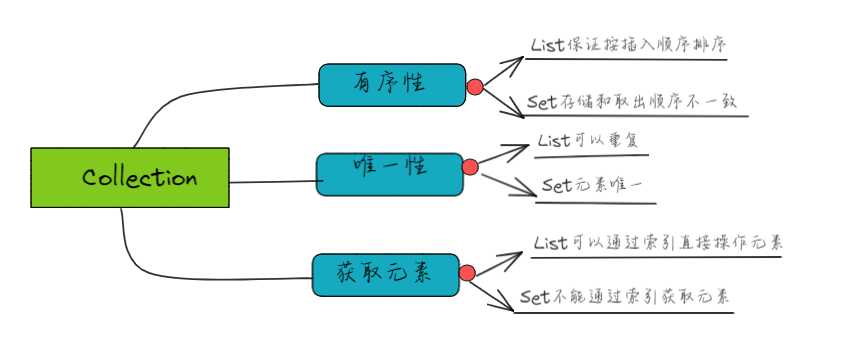
五 、Set集合
- 没有顺序(添加和取出元素的顺序不一致),没有索引
- 添加的元素不允许重复,最多只能包含一个null
- 主要有两个常用的实现类:HashSet 类和 TreeSet类
①实践操作
由于Set 属于接口,我们以Set 接口的实现类HashSet 来演示
package com.xiezhr;
import java.util.HashSet;
public class SetDemo {
public static void main(String[] args) {
HashSet hashSet = new HashSet();
hashSet.add("海贼王");
System.out.println(hashSet.add("海贼王"));
System.out.println("set添加元素后结果" + hashSet);
}
}
false
set添加元素后结果[海贼王]
从上面示例中,我们发现往set集合中添加重复元素是不允许的
5.1 HashSet类
HashSet 是 Set 接口的典型实现,大多数时候使用 Set 集合时就是使用这个实现类
HashSet 是按照 Hash 算法来存储集合中的元素。因此具有很好的存取和查找性能
不能保证元素的排列顺序,顺序可能与添加顺序不同,顺序也有可能发生变化
HashSet 不是同步的,如果多个线程同时访问或修改一个 HashSet,则必须通过代码来保证其同步
集合元素值可以是 null
当向HashSet 集合中存入一个元素时,HashSet会通过获取元素的hashcode 值来确定元素在HashSet集合中的存储位置。如果两个元素equale比较为true但是hashcode不相等,这两个元素也被当作时不同的元素,存储在不同的位置
HashSet 有常见的两种构造方法
HashSet() 构造一个新的空集合HashSet(Collection<? extends E> c) 构造一个包含指定集合中的元素的新集合
实践操作,用HashSet 创建一个,并向集合中添加几个动漫,并通过不同方式遍历集合
package com.xiezhr;
import java.util.HashSet;
import java.util.Iterator;
public class SetDemo {
public static void main(String[] args) {
HashSet hashSet = new HashSet();
hashSet.add("海贼王");
hashSet.add("火影忍者");
hashSet.add("鬼灭之刃");
hashSet.add("间谍过家家");
System.out.println("hashSet添加元素后:" + hashSet);
System.out.println("------------------通过过滤器 Iterator 遍历hashSet集合-------------------------");
Iterator iterator = hashSet.iterator();
while (iterator.hasNext()){
System.out.println(iterator.next());
}
System.out.println("------------------通过增强for循环 遍历hashSet集合-------------------------");
for (Object o : hashSet) {
System.out.println(o);
}
}
}
hashSet添加元素后:[火影忍者, 间谍过家家, 鬼灭之刃, 海贼王]
------------------通过过滤器 Iterator 遍历hashSet集合-------------------------
火影忍者
间谍过家家
鬼灭之刃
海贼王
------------------通过增强for循环 遍历hashSet集合-------------------------
火影忍者
间谍过家家
鬼灭之刃
海贼王
5.2 TreeSet
- TreeSet 类同时实现了 Set 接口和 SortedSet 接口。使用 TreeSet 类实现的 Set 接口默认情况下是自然排序的,这里的自然排序指的是升序排序
- TreeSet 只能对实现了 Comparable 接口的类对象进行排序
TreeSet 类除了实现 Collection 接口的所有方法之外

实践操作:我们将一组学生的成绩【68.0,50.5,78.6,88.0,95.0,45.5】 存入TreeSet,并进行TreeSet 集合的基本操作演示
package com.xiezhr;
import java.util.*;
public class TreeSetDemo {
public static void main(String[] args) {
TreeSet<Double> scoreSet = new TreeSet<Double>();
scoreSet.add(68.0);
scoreSet.add(50.5);
scoreSet.add(78.6);
scoreSet.add(88.0);
scoreSet.add(95.0);
scoreSet.add(45.5);
System.out.println("添加分数后的scoreSet:" + scoreSet);
Iterator<Double> it = scoreSet.iterator();
System.out.println("学生分数从低到高的排序为:");
while (it.hasNext()) {
System.out.print(it.next() + "\t");
}
if (scoreSet.contains(90.0)) {
System.out.println("成绩为: " + 90.0 + " 存在!");
} else {
System.out.println("成绩为: " + 90.0 + " 不存在!");
}
System.out.println("\n不及格的有:");
SortedSet<Double> score1 = scoreSet.headSet(60.0);
for (int i = 0; i < score1.toArray().length; i++) {
System.out.print(score1.toArray()[i] + "\t");
}
System.out.println("\n90 分以上的有:");
SortedSet<Double> score2 = scoreSet.tailSet(90.0);
for (int i = 0; i < score2.toArray().length; i++) {
System.out.print(score2.toArray()[i] + "\t");
}
}
}
添加分数后的scoreSet:[45.5, 50.5, 68.0, 78.6, 88.0, 95.0]
学生分数从低到高的排序为:
45.5 50.5 68.0 78.6 88.0 95.0 成绩为: 90.0 不存在!
不及格的有:
45.5 50.5
90 分以上的有:
95.0
5.3 LinkedHashSet类
LinkedHashSet: LinkedHashSet 是 HashSet 的子类,并且其内部是通过 LinkedHashMap 来实现的。有点类似于我们之前说的 LinkedHashMap 其内部是基于 HashMap 实现一样,不过还是有一点点区别
六、List和Set区别
七 、Map集合
Map 是一种键-值对(key-value)集合,Map 集合中的每一个元素都包含一个键(key)对象和一个值(value)对象Map 用于保存具有映射关系的数据key 和value都可以是任何引用类型的数据Map 的 key 不允许重复,value 可以重复Map 中的 key 和 value 之间存在单向一对一关系,即通过指定的 key,总能找到唯一的、确定的 valueMap 接口主要有两个实现类:HashMap 类和 TreeMap 类。其中,HashMap 类按哈希算法来存取键对象,而 TreeMap 类可以对键对象进行排序
Map 常用方法
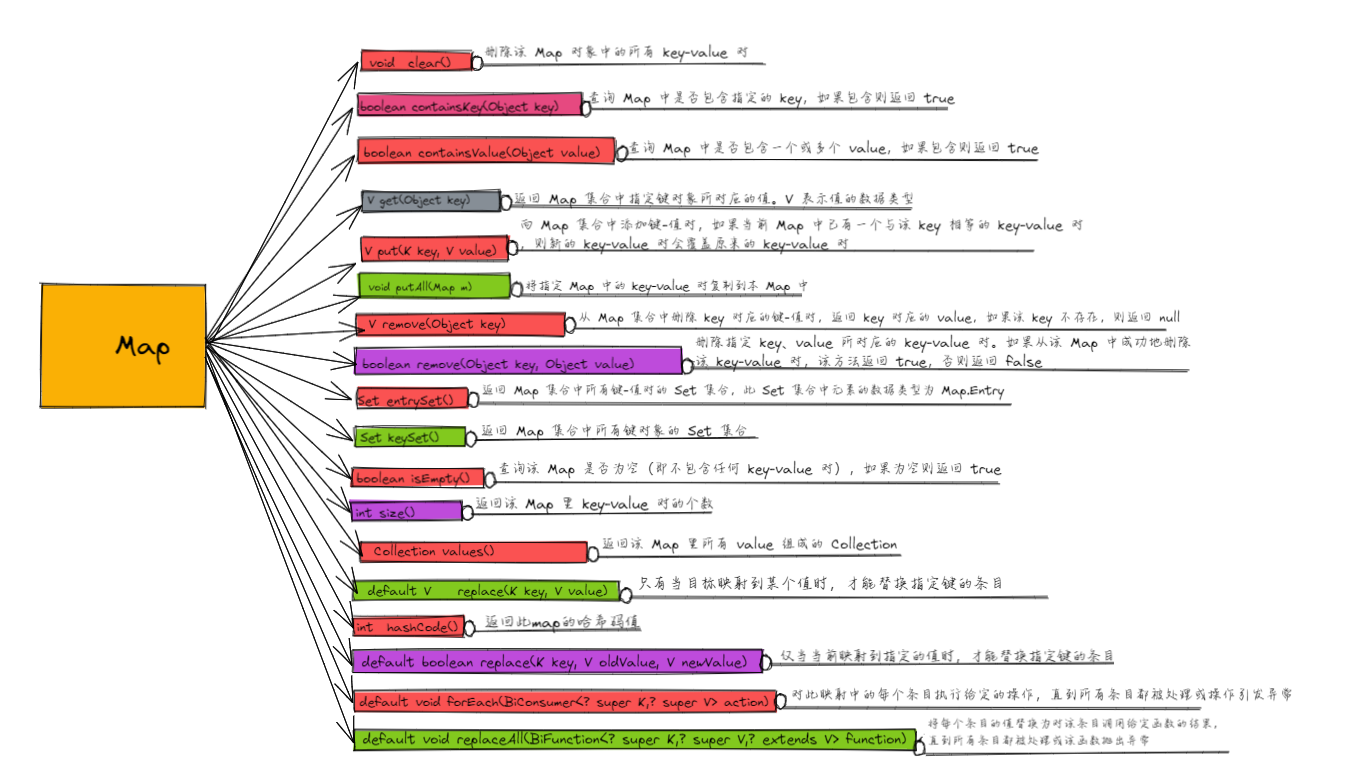
7.1 HashMap
- Hashmap 是一个最常用的Map,它根据键的HashCode 值存储数据,根据键可以直接获取它的值,具有很快的访问速度
- 遍历时,取得数据的顺序是完全随机的
- HashMap最多只允许**一条记录的键为Null;**允许多条记录的值为Null
- HashMap不支持线程的同步,即任一时刻可以有多个线程同时写HashMap;可能会导致数据的不一致。如果需要同步,可以用Collections的synchronizedMap方法使HashMap具有同步的能力
7.2 LinkedHashMap
- 保存了记录的插入顺序,在用Iterator遍历LinkedHashMap时,先得到的记录是先插入的,也可以在构造时用带参数,按照应用次数排序,需要输出的顺序和输入的相同,那么用LinkedHashMap可以实现
- 遍历的时候会比HashMap慢,不过有种情况例外,当HashMap容量很大,实际数据较少时,遍历起来可能会比LinkedHashMap慢
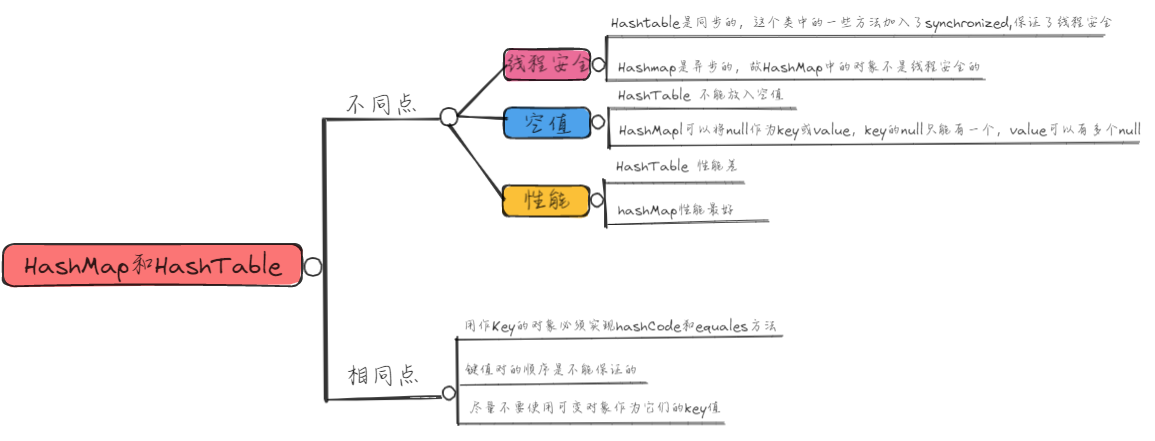
7.3 HashTable
- Hashtable 与 HashMap类似,不同的是:它不允许记录的键或者值为空
- 它支持线程的同步,即任一时刻只有一个线程能写Hashtable,因此也导致了Hashtale在写入时会比较慢
7.4 HashMap和HashTable比较
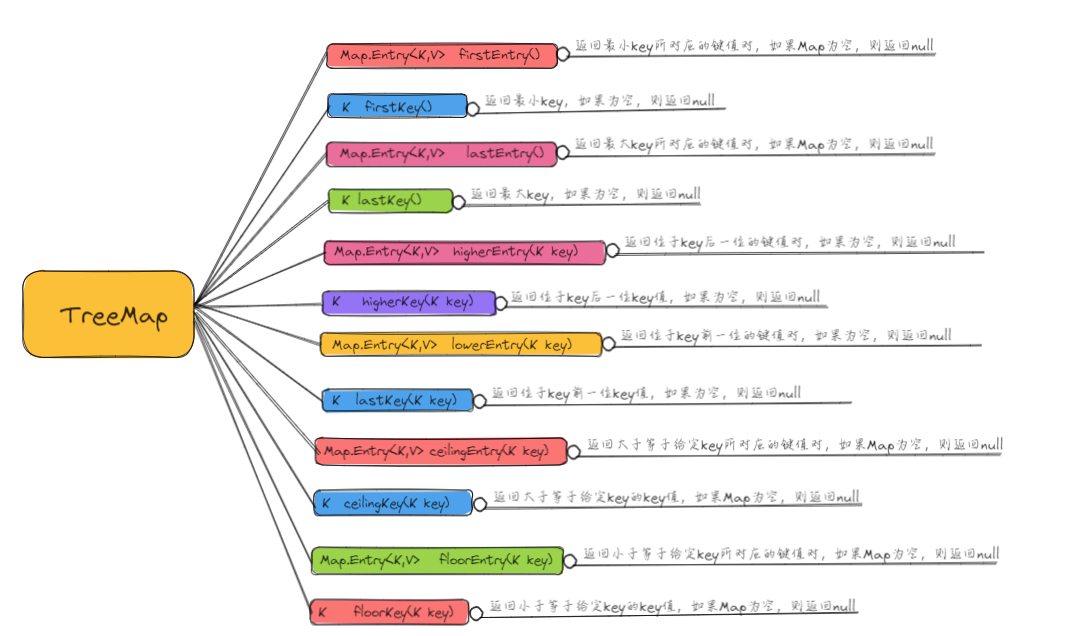
7.5 TreeMap
TreeMap实现SortMap接口,内部实现是红黑树- 能够把它保存的记录根据键排序,默认是按键值的升序排序,也可以指定排序的比较器,当用
Iterator 遍历TreeMap时,得到的记录是排过序的
TreeMap不允许key的值为null。非同步的
TreeMap 除了具有Map通用方法之外,还有自己特殊的方法
八 、Iterator 与 ListIterator
8.1 Iterator
Iterator是一个接口,它是集合的迭代器。在前面的示例中我们已经使用过,集合可以通过Iterator去遍历集合中的元素
Iterator 常用的API主要有以下几类
| – |
– |
boolean hasNext() |
判断集合里是否存在下一个元素。如果有,hasNext()方法返回 true |
Object next() |
返回集合里下一个元素 |
void remove() |
删除集合里上一次next方法返回的元素 |
package com.xiezhr;
import java.util.*;
public class IteratorDemo {
public static void main(String[] args) {
ArrayList<String> arrayList = new ArrayList<>();
arrayList.add("西游记");
arrayList.add("红楼梦");
arrayList.add("三国演义");
arrayList.add("水浒传");
System.out.println("添加元素后arrayList:" + arrayList);
Iterator<String> iterator = arrayList.iterator();
while (iterator.hasNext()){
String book = iterator.next();
if("红楼梦".equals(book)){
iterator.remove();
}
}
System.out.println("删除红楼梦后arrayList:" + arrayList);
}
}
添加元素后arrayList:[西游记, 红楼梦, 三国演义, 水浒传]
删除红楼梦后arrayList:[西游记, 三国演义, 水浒传]
注意:
8.2 ListIterator
ListIterator是一个功能更加强大的迭代器, 它继承于Iterator接口,只能用于各种List类型的访问- 可以通过调用
listIterator()方法产生一个指向List开始处的ListIterator
- 还可以调用
listIterator(n)方法创建一个一开始就指向列表索引为n的元素处的ListIterator
- 可以双向移动(向前/向后遍历)
- 可以使用
set()方法替换它访问过的最后一个元素
- 可以使用
add()方法在next()方法返回的元素之前或previous()方法返回的元素之后插入一个元素
package com.xiezhr;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.ListIterator;
public class ListIteratorDemo {
public static void main(String[] args) {
ArrayList<String> arrayList = new ArrayList<String>();
arrayList.add("西游记");
arrayList.add("红楼梦");
arrayList.add("三国演义");
arrayList.add("水浒传");
System.out.println("arrayList添加元素后 : " + arrayList);
ListIterator<String> it = arrayList.listIterator();
System.out.println("-------------------获取前后索引和当前值--------------------");
while (it.hasNext()) {
System.out.println(it.next() + ", " + it.previousIndex() + ", " + it.nextIndex());
}
System.out.println("-----------------------从后向前遍历-----------------------");
while (it.hasPrevious()) {
System.out.print(it.previous() + " ");
}
System.out.println();
System.out.println("------------------从指定索引开始遍历---------------------");
it = arrayList.listIterator(2);
while (it.hasNext()) {
String t = it.next();
System.out.println(t);
if ("三国演义".equals(t)) {
it.set("少年包青天");
} else {
it.add("xiezhr");
}
}
System.out.println("操作后的arrayList : " + arrayList);
}
}
arrayList添加元素后 : [西游记, 红楼梦, 三国演义, 水浒传]
-------------------获取前后索引和当前值--------------------
西游记, 0, 1
红楼梦, 1, 2
三国演义, 2, 3
水浒传, 3, 4
-----------------------从后向前遍历-----------------------
水浒传 三国演义 红楼梦 西游记
------------------从指定索引开始遍历---------------------
三国演义
水浒传
操作后的arrayList : [西游记, 红楼梦, 少年包青天, 水浒传, xiezhr]
九、集合使用场景
既然有这么多类型的集合供我们使用,那么我们应该怎么选择呢?
9.1 Collection接口选择
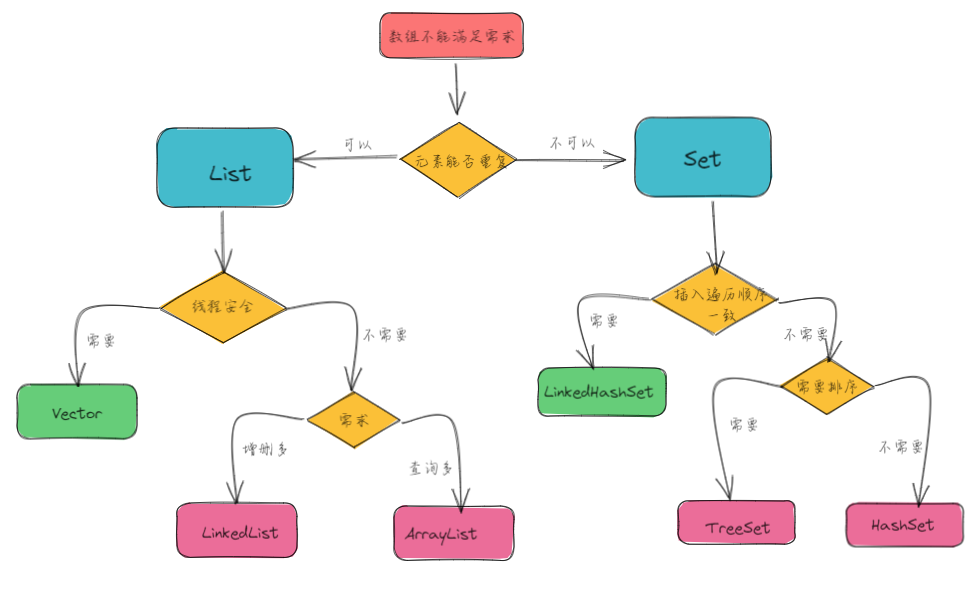
9.2 Map接口选择
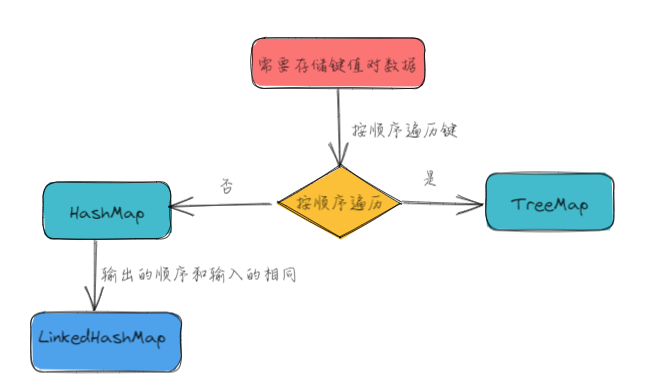
示例:
package com.xiezhr;
import java.util.*;
public class MapDemo {
public static void main(String[] args) {
HashMap<String,String> hashMap = new HashMap<>();
hashMap.put("4","d");
hashMap.put("3","c");
hashMap.put("2","b");
hashMap.put("1","a");
Iterator<String> iteratorHashMap = hashMap.keySet().iterator();
System.out.println("----------------------HashMap--------------------------");
while (iteratorHashMap.hasNext()){
Object key1 = iteratorHashMap.next();
System.out.println(key1 + "--" + hashMap.get(key1));
}
System.out.println("----------------------LinkedHashMap--------------------------");
LinkedHashMap<String,String> linkedHashMap = new LinkedHashMap<>();
linkedHashMap.put("4","d");
linkedHashMap.put("3","c");
linkedHashMap.put("2","b");
linkedHashMap.put("1","a");
Iterator<String> iteratorlinkedHashMap = linkedHashMap.keySet().iterator();
while (iteratorlinkedHashMap.hasNext()){
String key2 = iteratorlinkedHashMap.next();
System.out.println(key2 + "--" + linkedHashMap.get(key2));
}
TreeMap<String,String> treeMap = new TreeMap<>();
treeMap.put("4","d");
treeMap.put("3","c");
treeMap.put("2","b");
treeMap.put("1","a");
Iterator<String> iteratorTreeMap = treeMap.keySet().iterator();
System.out.println("----------------------treeMap--------------------------");
while (iteratorTreeMap.hasNext()){
String key3 = iteratorTreeMap.next();
System.out.println(key3 + "--" + treeMap.get(key3));
}
}
}
----------------------HashMap--------------------------
1--a
2--b
3--c
4--d
----------------------LinkedHashMap--------------------------
4--d
3--c
2--b
1--a
----------------------treeMap--------------------------
1--a
2--b
3--c
4--d
十、阿里Java开发手册规约
❶【强制】 关于hashCode和equals的处理,遵循如下规则
1)只要复写equals,就必须覆写hashCode。
2)因为Set存储的是不重复的对象,所以以及hashCode和equals进行判断,Set存储的对象必须覆写这两种方法
3)如果自定义对象作为Map的键,那么必须覆写hashCode和equals
说明:String因为覆写了hashCode和equals方法,所以可以愉快的将对象作为key使用
❷【强制】 判断所有集合内部元素是否为空,应该用isEmpty()方法,而不是使用size()==0的方式
说明:在某些集合中,前者的时间复杂度为O(1),可读性更好
正例:
Map<String,Object> map = new HashMap<>(16);
if(map.isEmpty()){
System.out.println("no element in this map.")
}
❸【强制】 在使用 java.util.stream.Collectors类的toMap()方法转为Map集合时,一定要使用含以后参数类型为BinaryOperator、参数名为mergeFunction的方法,否则出现相同 key值时,会抛出IllegalStateException异常。
说明: 参数mergeFunction 的作用是当出现key重复时,自定义对value的处理策略。
正例:
List<Pair<String,Double>> pairArrayList = new ArrayList<>(3);
pairArrayList.add(new Pair<>("version",6.19));
pairArrayList.add(new Pair<>("version",10.24));
pairArrayList.add(new Pair<>("version",13.14));
Map<String,Double> map = pairArrayList.stream().collect(Collectors.toMap(Pair::getKey,pair::getValue,(v1,v2)->v2));
反例:
String[] words = new String[]{"w","w","x"}
Map<Integer,String> map = Arrays.stream(words).collect(Collectors.toMap(String::hashCode,v->v))
❹【强制】 在使用java.util.stream.Collectors 类的toMap()方法转为Map集合时,一定要注意当value为null时,会抛出异常。
说明: 在java.util.HashMap的merge方法中,会进行如下判断:
if(value == null ||remappingFunction ==null)
throw new NullPointerException();
反例:
List<Pair<String,Double>> pairArrayList = new ArrayList<>(2);
pairArrayList.add(new Pair<>("version1",4.22));
pairArrayList.add(new Pair<>("version2",null));
Map<String,Double> map = pairArrayList.stream().collect(
Collectors.toMap(Pair::getKey,Pair::getValue,(v1,v2)->v2);
)
❺【强制】 ArrayList的subList结果不可强转成ArrayList,否则会抛出ClassCastException异常,即java.util.RandomAccessSubList canot be cast to java.util.ArrayList.
说明:subList() 返回的时ArrayList的内部类SubList,并不是ArrayList本身,而是ArrayList的一个试图,对应SubList的所有操作最终会反映到原列表上
❻【强制】 使用Map的方法keySet()/values()/entrySet()返回集合对象时,不可以对其添加元素,否则会抛出UnsupportedOperationException异常
❼【强制】 Collections类返回的对象,如:emptyList()/singletonList() 等都是immutable list,不可对其添加或者删除元素。
反例:
如果查询无结果,返回Collections.emptyList()空集合对象,调用方一旦进行了添加元素的操作,就会触发UnsupportedOperationException异常
❽【强制】 在subList场景中,高度注意对父集合元素的增加火删除,它们均会导致子列表的遍历、增加、删除产生ConcurrentModificationException异常。
❾【强制】 使用集合转数组的方法,必须使用集合的toArray(T[] array),传入的是类型完全一致、长度为0的空数组。
反例:
直接使用toArray无参方法存在问题,此方法返回值只能是Object[] 类,若强转成其他类型数组,将出现ClassCastException 异常
正例:
List<String> list = new ArrayList<>(2);
list.add("guan");
list.add("bao");
String [] array = list.toArray(new String[0]);
说明: 使用toArray带参方法,数组空间大小为length
1)等于0,动态创建于size相同的数组,性能最好
2) 大于0但小于size,重新创建大小等于size的数组,增加GC负担
3)等于size,在高并发情况下,在数组创建完成之后,size正在变大的情况下,负面影响与第二条相同
4)大于size,空间浪费,且在size处插入null值,存在NPE隐患
❿【强制】 在使用Collection接口任何实现类的addAll()方法时,都要对输入的集合参数进行NPE判断。
说明:ArrayList#addAll方法的第一行代码即Object[] a = c.toArray();
其中,c为输入集合参数,如果为null,则直接抛出异常
⓫ 【强制】 当使用工具类Arrays.asList()把数组转换成集合时,不能使用其修改集合相关的方法,它的add/remove/clear方法会抛出UnsupporedOperationException异常。
说明:asList的返回对象时一个Arrays内部类,并没有实现集合的修改方法。Arrays.asList体现的时适配器模式,知识转换接口,后台的数据认识数组。
String[] str = new String[] {"yang",“hao”};
List list =Arrays.asList(str);
第一种情况:list.add("yangguanbao");运行时异常。
第二种情况:str[0] = "changed"; 也会随之修改,反之亦然
⓬ 【强制】 泛型通配符<? extends T> 用来接收返回的数据,此写法的泛型集合不能使用add方法,而<? supper T> 不能使用get方法,因为两者在接口调用赋值的场景中容易出错。
说明: 扩展介绍一下PECS(Producer Extends Consumer Super)
原则:第一,频繁往外读取内容的,适合用<? extends T> ;
第二,经常往里插入的,适合用<? super T>。
⓭【强制】 在无泛型限制定义的集合赋值给泛型限制的集合中,当使用集合元素时,需要镜像instanceof判断,避免抛出ClassCastException异常。
说明:比较泛型是在JDK5后才出现的,考虑到向前兼容,编译器允许非泛型集合与泛型集合相互赋值。
反例:
List<String> generics = null;
List notGenerics = new ArrayList(10);
notGenerics.add(new Object());
notGenerics.add(new Integer(1));
generics = notGenerics;
String string = generics.get(0);
⓮ 【强制】 不要再foreach循环中对元素进行remove/add操作。当进行remove操作时,请使用Iterator方式。如果时并发操作,需要对Iterator对象加锁。
正例:
List<String> list = new ArrayList<>();
list.add("1");
list.add("2");
Iterator<String> iterator = list.iterator();
while(iterator.hasNext()){
String item = iterator.next();
if(删除元素条件){
iterator.remove();
}
}
反例:
for(String item : list){
if("1".equals(item)){
list.remove(item);
}
}
说明:执行结果肯定会出乎大家的意料,试一下把“1”换成“2”,会是同样的结果吗?
⓯ 【强制】 再JDK7及以上版本中,Comparator实现类要满足三个条件,否则Arrays.sort、Collections.sort 会抛出IllegalArgumentException异常。
说明: 三个条件如下
1)x,y的比较结果和y,x的比较结果相反。
2)若x>y,y>z , 则x>z。
3)若x=y,则x,z的比较结果和y,z的比较结果相同。
反例:下列中没有处理相等的情况,交换两个对象判断结果并不相反,不符合第一个条件,在实际使用中可能会出现异常
new Comparator<Student>(){
@Override
public int compare(Student o1,Student o2){
return o1.getId()>o2.getId() ? 1:-1;
}
}
⓰ 【推荐】 当使用泛型集合定义时,在 JDK7及以上版本中,使用diamond语法或全省略。
说明: 菱形泛型即diamond,直接使用<>指代前边已经指定的类型
⓱【推荐】 当集合初始化时,指定集合初始值大小
说明: HashMap 使用HashMap(int initialCapacity) 初始化,如果暂时无法确定集合大小,那么指定默认值(16)即可。
正例:initialCapacity =(需要存储的元素个数/负载因子)+1.
注意负载因子(即 loader factor)默认为0.75,如果暂时无法确定初始值大小,则设置为16(即默认值)。
反例:HashMap 需要放置1024 个元素,由于没有设置容量初始大小,则随着元素的增加而被迫不断扩容,resize()方法一给一共会调用8次,反复重建哈希表和数据迁移。当放置的集合元素规模达到千万时,会影响程序性能
⓲ 【推荐】使用entrySet 遍历Map类集合K/V,而不是用keySet方式遍历。
说明: keySet 方式其实遍历了两次,一次时转为Iterator对象,另一次时从hashMap中取出Key所对应的Value。而entrySet只遍历了一次九八Key和Value都放到了entery中,效率更高。如果是JDK8、则使用Map.forEach方法。
正例: values()返回的V值集合,是一个list集合对象;keySet()返回的是K值集合,是一个Set集合对象;entrySet()返回的是K-V值组合集合。
⓳ 【推荐】 高度注意Map类集合K/V能否存储null值,如表1-1所示。
表1-1 Map类集合K/V存储
| 集合类 |
Key |
Value |
Super |
说明 |
Hashtable |
不允许为null |
不允许为null |
Dictionary |
线程安全 |
Concurrent HashMap |
不允许为null |
不允许为null |
AbstractMap |
锁分段技术 |
TreeMap |
不允许为null |
允许为null |
AbstractMap |
线程不安全 |
HashMap |
允许为null |
允许为null |
AbstractMap |
线程不安全 |
反例:由于HashMap的干扰,很多人认为ConcurrentHashMap可以置入null值,而事实上,在存储null值时,会抛出NPE异常。
⓴ 【参考】 合理利用好集合的有序性(sort)和稳定性(order),避免集合的无序性(unsort)和不稳定性(unorder)带来的负面影响。
说明:有序性指遍历的结果按某中比较规则依次排列。稳定性指集合每次遍历的元素次序时一定的。如:ArrayList是order/unsort;
HashMap是unorder/unsort; TreeSet是order/sort。
以上就是本期全部内容,希望对你有所帮助,我们下期再见 (●’◡’●)